Which to tune ? Application, Database or Hardware ?
- kyle Hailey
- May 27, 2014
- 5 min read

I. “The Database is hanging!” AKA “the application has problems, good grief”
I wonder if you can imagine, or have had the experience of the application guys calling with anger and panic in their voices saying “the database is sooo slow, you’ve got to speed it up.”
What’s your first reaction? What tools do you use? How long does it take to figure out what’s going on?
When I get a call like this I take a look at the database with “Top Activity” screen in Oracle EM or a tool like Lab 128 or DB Optimizer. All of these tools have a screen that shows Average Active Sessions (AAS) over time and grouped into their wait groups and all these tools use the same color coding for the wait groups:

From the above chart, I can clearly see that the database is not bottlenecked and there must be a problem on the application.
Why do I think it’s the application and not the database? The database is showing plenty of free CPU in the load chart, the largest chart, on the top, in the image above. In the load chart, there is a horizontal red line. The red line represents the number of CPU’s on the system, which in this case is 2 CPUs. The CPU line is rarely crossed by bars which represent the load on the database, measured in average number of sessions or AAS. The session activity is averaged over 5 samples over 5 seconds, thus bars are 5 seconds wide. The bars above fall mostly about 1 AAS and the bars are rarely green. Green represents CPU load. Any other color bar indicates a sessions waiting. The main wait in this case is orange, which is log file sync, ie waits for commits. Why is the database more or less idle and why are most of the waits we do see for “commit”? I look at the code coming to the database and see something like this:
insert into foo values ('a');
commit;
insert into foo values ('a');
commit;
insert into foo values ('a');
commit;
insert into foo values ('a');
commit;
insert into foo values ('a');
commit;
insert into foo values ('a');
commit;
insert into foo values ('a');
commit;
Doing single row inserts and committing after each is very inefficient. There is a lot of time wasted on network communication which is why the database is mainly idle, when the application thinks it’s running full speed ahead, it is actually waiting mainly on network communication and commits. It’s like going to the grocery store with a long list of things to buy but only buying one and then going home dropping it off and then going back to the grocery store. In this databse example, if we were to commit less and batch the work we send to the database, reducing network communications, we will run much more efficiently. Changing the code to
begin
for i in 1..1000 loop
insert into foo values ('a');
-- commit;
end loop;
end;
/
commit;
reduces the communication delay and now we get a fully loaded database but we run into database configuration issues.
II. It *is* the database (ie DBA get to work)
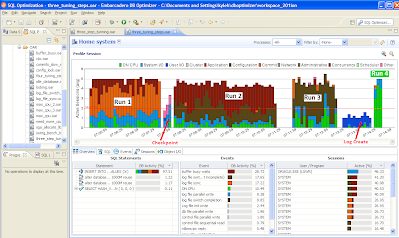
In the above DB Optimizer screen, the same workload was run 4 times, which created 4 large colored areas in the chart labled “Run 1″, “Run 2″, “Run 3″ and “Run 4″. We can see that the time (width of the load) reduced, and the percent of activity on CPU increased over each succeeding run. What happened differently in each of these runs
Runs:
“log file sync” , the orange color, is the biggest color area, which means uses are waiting on commits, still even though we are committing less in the code. In this case we moved the log files to a faster device. (you can see the checkpoint activity in light blue just after run 1 where we moved the log files)
“buffer busy wait” , the burnt red, is the biggest color area. We drilled down on the buffer busy wait event in the Top Event section and the details instruct use to move the table from a normal tablespace to an Automatice Segment Space Managed (ASSM) tablepace.
”log file switch (checkpoint incomplete)” , the dark brown, is the largest color area, so we increased the size of the log files. (you can see the IO time spent creating the new redo logs just after run 3 )
the run time is the shortest and all the time is spent on the CPU which was our goal – ie to take advantage of all the processors and run the batch job as quickly as possible.
III. It’s the machine (rock paper scissors)
Now that the application is tuned and the database is tuned let’s run a bigger load:

We can see that the CPU load is constantly over the max CPU line. How can we have a bigger CPU load than there are actually CPUs on the machine? Because, this actually means that the demand for CPU is higher than the CPU available on the machine. In the image above there are 2 CPUs on the machine but and average of 3 users who think they are on the CPU, which means that on average 1 users is not really on the CPU but ready to run on the CPU and waiting for the CPU.
At this point we have two options: either add more CPU or tune the application code. In this case we are only running one kind of load, ie the insert.
If we look at the bar chart to the bottom right of the load chart, we see that the top bar is much larger than the ones below this. This bar represents the SQL statement with the largest load. In this case our insert statement is the highest load SQL so we can concentrate on tuning that statement.
For inserts we can actually go even further tuning this insert and use Oracle’s bulk load commands:
declare
TYPE IDX IS TABLE OF Integer INDEX BY BINARY_INTEGER;
MY_IDX IDX;
BEGIN
for i in 1..8000 loop
MY_IDX(i):=1;
end loop;
FORALL indx IN MY_IDX.FIRST .. MY_IDX.LAST
INSERT INTO foo ( dummy )
VALUES ( MY_IDX(indx) );
COMMIT;
end;
/
Using the above code the load runs almost instantaneously and creates almost no visible load in the load chart!
What if on the other hand there was no out standing SQL taking up most of the load ? and instead the SQL load was well distributed across the system? Then we’d have a case for adding more hardware to the system. Making the decision to add more hardware can be a difficult decision because in general the information to make the decision is unknown, unclear or just plain confusing, but the “Top Activity” chart along with top SQL bar chart makes it easy and clear, which can save weeks and months of wasteful meetings and debates. For example

If we look in the bottom left, there is no SQL that takes up a significant amount of load, ie there is no outlier SQL that we could tune and gain back a lot of wasted CPU. We’d have to tune many many SQL and make improvements on most of them to gain back enough CPU to get our load down below the max CPU line. In this case, adding CPUs to the machine might be the easiest and most cost affective solution.
Conclusion:
With the load chart we can quickly and easily identify the bottlenecks in the database, take corrective actions, and see the results. In part I we had an application problem, in part II we had 3 database configuration issues and in part III we had a hardware sizing issue. In all 3 cases the load cahrt provides a clear and easy presentation of the data and issues making solutions clear.



Comments