DevOps Jetpack for Developers: Jetstream Setup
- kyle Hailey
- Oct 13, 2015
- 4 min read

Delphix has a developer self service interface called “Jetstream.” I like to call it the “DevOps Jetpack” for developers.
Jetstream is available both in the Delphix enterprise engine and also in the free Delphix Express engine.
Here is a video on how to setup Jetstream for two users, a developer (Joe Dev) and a QA analyst (Jane QA). In a blog post to follow this one, we will see how Joe Dev and Jane QA can work together thanks to Jetstream which allows them to share versions of data (similar to how people can share versions of code with source control).
steps
create users
create a template (defining what virtual data will be in a container)
create virtual data for the containers
create containers with virtual data following the template definition
by step 4 the users will be able to log in and have self service to refresh, rollback, bookmark, branch etc for all the data in the container. If there are multiple data sources defined in the container then when refreshing or booking marking, everything will be refreshed or bookmarked in sync.
Create Users
The first step is to create a couple users accounts for the developers and QA people using Jetstream.

To create users, go to the top left menus and choose “Manage” then choose “Users”

After choosing “Manage -> Users” you see the following screen. On the following screen click the “+ Add User” button in top left, then on the right fill out users name, email address, password and be sure to click the “JS Only User” box.

For these examples I added two users “JaneQA” and “JoeDev”.
Setting up Jetstream
Jetstream organizes data sources work into a “Template”. A Template defines which data sources will be used together in a container. A container contains virtual data copies and belongs to a developer. All data copies in the container can be refreshed, bookmarked or otherwise operated on together and in sync.
Once a template had been defined, one can instantiate containers for users.
Create a Template
A template defines what data sources will be allocated in containers given to users. User containers are based on templates.

To create a template, go into the Jet Stream interface. To go into the Jet Stream interface, click on the “delphix_admin” in the top right, then choose “Jet Stream”

Now you are in the Jet Stream interface.
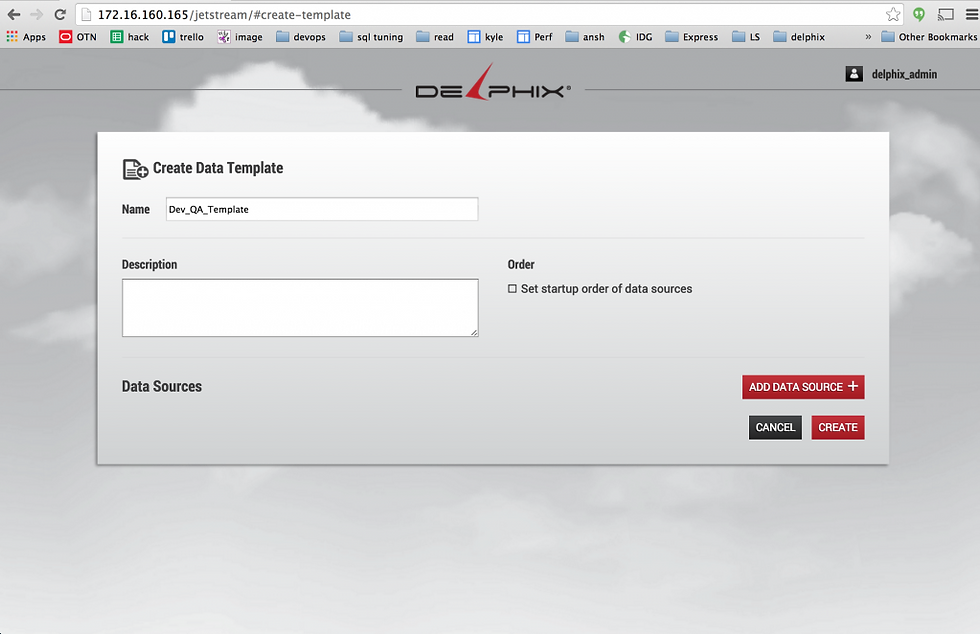
To create a template, click on “Add Template +” in the middle right.

Now name the template. I used “Dev_QA_Template”
Then click “Add Data Source +” in the bottom right.
For the first data source, choose the Employee XE database

The second data source to add is the Employee Web Application. Click “Add Data Source” and add the Employee Web Application.
Finally click “Create” and now you have a template for containers and can start creating containers for users.
Create Virtual Application Stack
Each user JaneQA and JoeDev will need virtual data copies of the XE database and the web app to put into the containers based on the above template.
We can provision a virtual web application and virtual XE database for each user. There is a trick in this lab situation. We are using XE databases so there can only be one XE instance per host, thus we have to create a second host if we want a second copy of the database for the second user. To get a second host for this lab, you can just re-import the target OVA. See
For the developer we set up “devdb” and “devapp” on one target and for the QA person we set up “qadb” and “qaapp” on the other host.

Above is what the admin screen looks like after create the development app stack copy and the development database copy. We also need to create another copy of the app and db for Jane QA.
Create Containers
Now that we have the template and virtual data copies to supply, we can make containers for uses

When you come in to Jet Stream, you will see the template we just created. Click on the name of the template.

After clicking on our template, you can create containers for that template clicking “Add Container” on the top right.

To create the container, give it a name and make sure that the owner is the correct user, in our case it will be JoeDev (then we will create one for JaneQA)
Choose the virtualized data sources to correspond to the definition of the template.

Users
When users log in, for example Joedev, the screen looks like

The middle of the screen shows that the data used by this user has been branched off from the data source at 10/12/2015 11:12:22am.
The red star is the current state of the the virtual data. We can click on any point in the time line to bookmarket or restore to.
Activate – start the database instance(s) and any application instances in the container
Bookmark – mark this spot to go back to or share with another uer
Branch – make a new read/write instantiation while still being able to go back to the old version
Share – make a bookmark shareable with other users
Refresh – refresh data from the current data sources state
Restore – restore data to a previous point in time
Reset – reset data to most recent bookmark
Stop – stop the database instance(s) and any application instances in the container
Some cool things:
If I was a performance person I could create multiple branches of the data perhaps with different index configurations and run the same performance tests across the different branches and compare. To go from branch to branch requires choosing the branch and activating it, which will deactivate any current activated branch.
If I was a QA person I could bookmark not only the application version with a bug but also the data state that has the bug because bugs are going to need example data to reproduce the bug and sometimes bugs are directly related to specific data data states.
We will look at how to use these features in future blog posts.



Comments